
No.

Thank you for reading!
OK, I kid. Of course, if you were to say artificial intelligence/machine learning could predict a perfect March Madness bracket, you would be technically correct. The best kind of correct!
It is not impossible to predict a perfect bracket, but the odds of predicting a perfect bracket are staggeringly low. Assuming you just flipped a coin to pick the winner of each game, the odds of you filling out a perfect bracket are estimated to be one in 9.2 quintillion. That’s 9.2 followed by 18 zeros!

Of course, there are better methods than flipping a coin; after all, a team’s performance isn’t random. Incorporating known statistics of the teams that made it to the tournament will undoubtably increase your odds of picking the correct team to advance. If you have some knowledge about basketball and include it in your decision making, your odds increase dramatically to about 1 in 120.2 billion according to this NCAA article. (and yes that is sarcasm, albeit still an accurate statement as those odds are substantially better than 1 in 9.2 quintillion.
From a data standpoint, there is an extreme wealth of stats out there available to the public so even if you don’t follow college basketball, you can still be just as well informed as an avid fan. You may be thinking “Hey, with all the data available and the crazy awesome advances in technology, compute power, machine learning and AI capabilities, it’s only a matter of time before someone comes up with an algorithm to predict a perfect bracket.” You may even be intending to try this yourself. I want to take this time to inform you that your model will likely crash and burn before round 1 is halfway complete. It is practically impossible to predict the outcome of each game because of what you can’t measure and what you can’t account for.
Why seeking to create the perfect bracket is a fruitless endeavor:
There are too many unknown variables.
In any sport, there are always unknown variables that can impact the outcome of a game. Just a few of these found in March Madness include the strategy that will be used by a team and its efficacy vs the opposing team, what mental state a player is in, the impact of the additional pressure on the players / teams. Without knowing these variables, and without having sufficient data to capture these and incorporate them into your model, your model won’t be able to model their relationship to a teams performance and the outcome of a match.
Each prediction is for a singular game under “non-normal” circumstances.
If you were to guess to try and predict a team’s overall record throughout the last third of their season based on data you fed into your model from the two-thirds of their seasons, you could likely achieve a very high degree of accuracy because the team’s performance will average out over time to how they are statistically expected to perform. If you were to switch to predicting a singular game and compared how many you got right vs wrong, you’d most likely find a much larger degree of error.
March Madness is a single elimination tournament. The nature of a single elimination tournament allows for the high variance variables and luck that influences a games outcome to carry greater weight as oppose to a “best of X” series. That being said, even in a tournament with a best-of series, predictions aren’t perfect, and stats don’t always prevail, but it does at least allow some smoothing out of the variance and luck.
There is High Variance in many of the predictive variables the model uses.
In basketball, there are numerous variables that can impact the outcome of a game, such as player performance, team strategy, game conditions, and opponent quality. These variables can have high variance, meaning that they can fluctuate widely and unpredictably from one game to another, and the reasons underlying this are hard to measure because they are often unknown.
For example, the shooting accuracy of a player can vary significantly depending on their physical and mental state, as well as the defensive pressure from the opposing team, all of which are unknown and change without warning. If a team heavily relies on a particular player for scoring, a high variance in their shooting performance can greatly affect the team’s overall scoring output.
A team’s strategy and play style can also be influenced by the high variance of variables. If a team’s preferred style of play heavily relies on fast breaks and aggressive defense, but the opponent’s tactics limit these opportunities, the team may struggle to adapt and perform as they would normally be expected.
Similarly, a player may thrive on the high stakes and perform better than they had during the regular season / earlier in their career. I don’t follow sports closely so there are probably better examples, but here’s two:
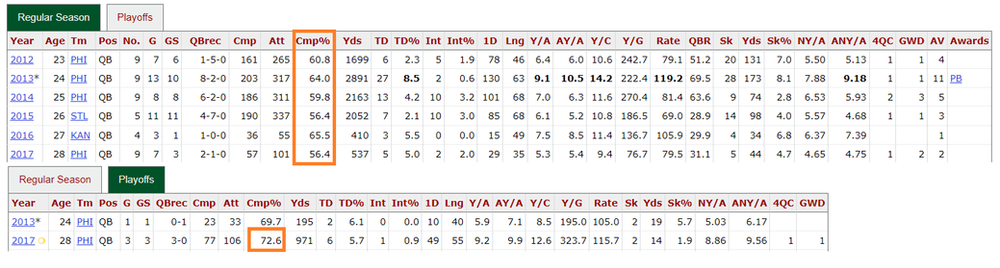
Nick Foles: Up until the end of regular season play in 2017, Foles had a pass completion rate of 60.01% yet in the post season he managed to post a 72.6% pass completion rate contributing greatly to the Eagles Superbowl victory that year.
Brian Doyle: In the first year of his career, Doyle’s batting average was .161 with 54 appearances at plate. I know next to nothing about baseball, but I do know that this is stat is very lack luster. However in the post season that same year, he appeared at bat 24 times and had a batting average of .391 which is outstanding, complete unexpected, and undoubtably contributed to the NY Yankees world series win that year.

Human emotion
This is probably the most significant factor that makes building a model to predict March Madness outcome unreliable because human emotion itself is impossible to model. The factors that affect this are often what make up the most memorable sporting moments. Even if all information about external factors was known, the impact a given event has on any one player or across the whole team is unpredictable. Teams can be motivated by different factors, such as revenge, pressure, or simply the desire to win.
Probably one of the best, and most feel good examples of this is right here:

So… what’s the point? Why should you even try?
While predicting a perfect bracket may be nearly impossible, building an ML model in an attempt to do so presents a fantastic learning opportunity and can still be a fun and valuable exercise. Not only does it provide an opportunity to practice working with data and building predictive models, but it also allows for friendly competition with colleagues and friends and the data community alike.
The data for March Madness is plentiful and easily accessible. Kaggle is a great source and you can add to this with information you supplement from other places around the web. Not only that, but the data is very easy to understand (once you know what the abbreviations stand for), and you can easily infer what the more important features of your model will be and focus your engineering on those which can allow you to jump into building the model a little faster than you would normally. After you have your data you can employ a variety of different algorithms in building your model and compare their performance to each other relatively easily, and you only have to do the data engineering once.
Lastly, every year, the tournament attracts a lot of attention from the data community and many data enthusiasts post their models, code, and results online. This affords a great opportunity to see how different feature engineering, model development, hyper parameter tuning can all have varying impact on prediction accuracy even when the same algorithms are used.
So, while the odds of predicting a perfect bracket may be insurmountable, the excitement of trying and the experience gained in the process make it a worthwhile endeavor. In my next blog post, I’ll provide guidelines for building a model to make a March Madness bracket.


