
How do you decide which AI model is best suited for a given task? Many people look to LLM Benchmark performance to compare how models compare to each other, but these benchmarks are highly sanitized and not always indicative of the problems that are being solved in production environments. That’s why, at Cleartelligence, we perform our own benchmarking of models, and we compare their performance to representative problems that our clients are trying to solve every day in production.
Here is a summary of our takeaways, and in what circumstances we suggest using each model in. For brevity, we are limiting the scope of this article to current SOTA OpenAI models, but many of the tradeoffs (when to use distilled models, when to use reasoning models) applies to models from other providers as well.
Note: In this article, “cheaper” models are also called “smaller” models, a reference to the number of parameters required to run inference.
Task 1: Information Extraction from PDF
One thing we use AI models for is information extraction from PDFs. Ideally, PDFs are in a consistent format, and we can use OCR techniques to extract the information we need. However, in the real world, the data is rarely consistent in location and even less consistent in formatting. The information we are looking for can be in multiple locations – or not be present at all. In those situations, we can use the AI models to parse large amounts of text for ambiguously formatted data.
Recent OpenAI models have boasted about their needle-in-a-haystack capabilities, claiming to be able to find what you’re looking for in up to 1 million tokens (i.e. looking for a single sentence in “Harry Potter and the Goblet of Fire”), but is this truly the case in practice? And how do the new models compare to the best performing previous-generation model (GPT-4o)?
To answer these questions, we developed our own internal benchmarks, representing the types of problems our clients are trying to solve every day. The results of the models can be seen in the table below:
Takeaways:
- GPT-4.1 was the best performing model, outperforming all models across all data extraction tasks.
- GPT-4.1-mini was comparable to 4o for most tasks but failed when dealing with domain-specific vocabulary
- GPT-4.1-nano was significantly worse across the board and was only good for very specific extraction tasks
- o4-mini (reasoning) was slightly better for the most involved extraction tasks but was not worth the extra time and reasoning tokens. No difference observed for different levels of reasoning.
For this, the only choice is between GPT-4.1 and GPT-4.1-mini, depending on how complex the extraction is. It appears that reasoning is not relevant for document extraction, except in the most complicated cases. OpenAI’s claims of improvement on needle-in-the-haystack performance seem justified!
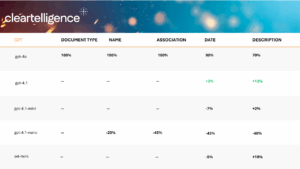
Note: Only showing difference compared to gpt-4o (previous most prominent)
Task 2: Direction Following
Direction following is an abstract task for LLMs, but it has become a focus for OpenAI as of late. The basic idea is that an LLM should be able to follow basic directions within a prompt, particularly instructions that don’t require reasoning. An instruction for an information extraction task could be to look for a specific value, or return ‘NOT FOUND’. Previous iterations of LLMs would return some value that it found in your document, whether it was the correct value or not, and they would often fail to return ‘NOT FOUND’ even when they should.
The more steps there are, and/or the more complicated each step is, the more reasoning is required. In general, we advise avoiding too many complicated steps at once, but sometimes it’s unavoidable. For simpler directions that don’t require any true data manipulation (i.e. simple “if/then” logic steps), GPT-4.1 can get the job done. For more complexity (i.e. solving an algebraic equation), moving to o3 or o4-mini justifies the increased cost and time requirements of these models. GPT-4.1-mini can be useful, but only in simple cases. We do not suggest using GPT-4o or GPT-4.1-nano for direction following tasks.
Based on the above guidelines, it should be clear which model type your situation requires. Even so, we always test the models side-by-side. If we don’t see a substantial jump in performance from reasoning models, we tend to stick with the normal ones.
Task 3: Domain-Specific Vocabulary
Many of the limitations we see with smaller models are from a lack of understanding of domain-specific terminology. By domain-specific terminology, we mean vocabulary that is used differently in different situations. For instance, a “bond” can mean one thing in finance, another thing in court, and something else in a chemistry lab.
For LLMs, this domain-specific vocabulary can be difficult, as they must be trained in these domains to understand the terminology properly. These smaller models, particularly GPT-4.1-nano, have a relatively limited learning capacity, so these more precise details can cause inaccuracies.
A larger model like GPT-4.1 or o3 will speak very fluently about most domains we’ve tested, from legal jargon to Wall Street vocabulary. For a smaller model, like GPT-4.1-nano, it reads like someone who read a couple Wikipedia articles on the topic and nothing more. Sometimes the model will even “punt” on an explanation and not return a valid answer. For this reason, we don’t trust GPT-4.1-nano to handle any tasks with nuance.
In our experience, reasoning models like o3 or o4-mini perform similarly well on domain-specific vocabulary as compared to GPT-4.1. If you enable tools like Web Search, a reasoning model can potentially outperform GPT-4.1 on extremely domain-specific vocabulary by googling it. However, this is only required in niche circumstances.
The easiest way to tell whether a model understands your domain is to ask some specific questions. By querying these models in domain-specific situations, it becomes obvious which models understand the domain and which models do not.
The Price Tradeoff: When should you use cheaper models?
Perhaps you are unsure whether a simple task can be done by GPT-4.1-nano instead of using GPT-4.1-mini. Or if a somewhat complex problem really warrants the use of the large GPT-4.1. Assuming the larger model performs slightly better, how do you decide when it is worth it?
In these cases, we like to run a cost-benefit analysis. First, identify what the cost of a failure is in your process. Does a failure require human-in-the-loop interaction? Does it lie undetected until it causes problems later down the line? How much time is required to fix the issue? Next, using some representative examples, estimate the likelihood of failure for each of the models in question. Finally, using those same examples, estimate how much more expensive each run of the larger model would be.
Now we can run the cost-benefit analysis. Let
- X = cost savings per run of the smaller model
- Y = % increased failure rate of the smaller model
- Z = cost of failure
The cutoff point exists when the cost savings equals the expected cost of failure, so when X = (Y/100) × Z. If X < (Y/100) × Z, the increase in cost for using the larger model is less than the cost of failure, so it makes sense to use the larger model. Conversely, if X > (Y/100) × Z, use the smaller model.
If you’re still unsure at this point, we usually recommend using the larger model. Most of the time, the increase in cost is minimal and the peace of mind is more than worth it.
Main Takeaways:
- Information Extraction from PDF: Any new model can be used for PDF information extraction. Choose larger models if information format is inconsistent.
- Direction Following: For most direction-following tasks, GPT-4.1 or GPT-4.1-mini is sufficient, but more complex tasks requiring reasoning justify the increased cost and time of o3 or o4-mini models.
- Domain-Specific Vocabulary: A main limitation of smaller models is their inability to understand domain-specific vocabulary.
- Choosing Models: A cost-benefit analysis can help identify which models work best at scale, but for low-volume workflows or close calls, use the larger, more reliable model.
At Cleartelligence, we specialize in breaking down complex workflows, optimizing for cost savings, and making sure your system delivers maximum value. If you want advising on your current project, or help scoping out, designing, or implementing future projects, reach out to our team of experts here.


