
Anyone who’s worked in sales or business development knows the drill. You spend hours every week crafting customized quotes, statements of work, and RFP responses. The work is repetitive and tedious, which is why many teams are exploring automated proposal generation. But each proposal needs to feel personal to your business and specific to what the customer wants. This nuance has made automation difficult – traditional tools and machine learning models couldn’t handle the complexity.
Generative AI changes the game. These new models can match your company’s tone. They can customize output for different customers, and work with your institutional knowledge. Many companies are now exploring how to automate the repetitive parts of proposal writing while keeping the output consistent and humans involved in the process.
Here’s the thing about GenAI: most companies give up when out-of-the-box solutions don’t work for their specific needs. We’ve found these generic solutions fall short because they lack the institutional knowledge that makes proposals effective – those unspoken, undocumented rules that make a huge difference in your output.
Custom systems bridge the gap between the capabilities of GenAI and your specific business needs. At Cleartelligence, we build these systems collaboratively with your subject matter experts, so your knowledge and tone get embedded directly into the workflow. Our systems are designed to ask humans for information when they need it, rather than guessing or (worse) hallucinating. These workflows mirror your existing process, often broken down into the same smaller steps you already follow.
We evaluate each step separately with custom benchmarks, which makes our systems model-agnostic. You can plug in any model – local or external – and compare performance on each task. Pick the best model for each sub-task. As models improve in cost and capability, you can easily test new ones against your current system and make a change based on performance. No additional investment required.
If this sounds interesting to you, here’s what a typical engagement with Cleartelligence would include:
Step 1: Effective Demo (1-4 weeks)
The goal with an Effective Demo is simple: prove that your process can be automated and that the model output meets your standards. One advantage of generative AI is speed to output, especially for straightforward cases. This makes it a cost-effective way to validate that GenAI can handle your workflow.
We build the Effective Demo around carefully selected subtasks from your workflow. Usually, we pick two subtasks. One simple subtask – something like formatting, tone matching, or producing expected output – to show how accurate these models can be. The second subtask focuses on one of your more complex challenges. This subtask lets us demonstrate how the model handles situations where it needs more information and how we incorporate the institutional knowledge that’s essential for success.
These subtasks also showcase our evaluation system. You’ll see how easily we can switch between specific models and how you can choose different models for different tasks based on cost, accuracy, and speed requirements.
Working with your internal experts during this phase serves two purposes. First, we identify the most representative subtasks for testing. Second, we start building a knowledge base of that internal, sometimes unspoken, institutional knowledge you rely on. We also pinpoint the major pain points and repetitive tasks that would be most valuable to automate.
Once the demo is complete, we present the results and discuss where the models excel and where they struggle. At this point, we have a much clearer picture of how the full workflow automation will perform for your specific system, and we can talk through next steps.
Step 2: Foundational Release (Human-in-the-Loop) (1-3 months)
The foundational release gives you the most basic version of a full workflow prototype. We expect to automate 50-80% of the workflow, focusing on the repetitive and tedious parts. The system works as a series of subtasks that can be processed in a queue or run concurrently, all connected to a shared internal knowledge base.
The workflow handles ingesting basic information on its own. But for complex details, it asks the human-in-the-loop. Once information gets sourced, the model stores it in the knowledge base so manual lookup for that specific information will not be required for the rest of the process. Think of it like TurboTax: the model identifies what information it needs for each subtask, pulls relevant details from the knowledge base, asks the human for anything missing, adds new information to the knowledge base, then drafts a response and sends it for manual review.
This isn’t RAG – it’s working memory. With RAG, you don’t know whether the answer to your question exists in your knowledge base. In our system, we know if the relevant information exists and can access it directly. If it doesn’t exist, we query the human. This prevents hallucinations and makes sure all model output is grounded and traceable back to source documents.
The human-in-the-loop process means all output gets verified and humans stay actively involved in creating the final product. But the entire process speeds up significantly.
Once the foundational release is ready, we deploy it into your architecture, and you can start using it immediately.
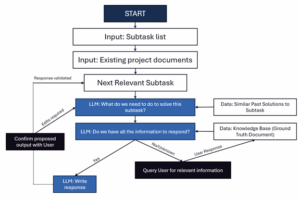
Figure 1: An example Human-in-the-loop workflow
Step 3: Full Implementation (Human-as-a-Supervisor) (2-6 months)
Once the foundational release is deployed and running, we analyze whether additional automation makes sense. Sometimes it does, sometimes it doesn’t. That decision depends on the complexity of the remaining tasks and whether the time savings justify the development cost.
If full implementation is worth pursuing, we monitor how the foundational release gets used to identify the main failure points and information gaps. These often fall into predictable patterns that we can address systematically.
Many foundational releases start with minimal data sources and rely on manual information gathering. We can implement structured information extraction pipelines to automatically populate the knowledge base, reducing the need for lookups.
The goal is to minimize manual intervention points. As we identify common intervention patterns and automate them, the role of the human in the workflow shifts from active participant to supervisor. Instead of being involved in every step, oversight becomes focused on process verification and handling exceptional circumstances (we always ensure the model asks for guidance when it’s uncertain).
Here’s what makes this approach powerful: input from supervisors gets implemented not just at the current report level, but feeds back into the entire system. When a supervisor makes changes or edits, that knowledge gets stored and applied to all future reports. The system dynamically improves over time based on supervisor feedback.
We aim to decrease both the number of interventions required and the failure rate so the process runs smoother than ever. If one or two steps can’t be automated, subject matter experts can handle them asynchronously in batches, removing bottlenecks from the main workflow.
Our model-agnostic design supports continuous improvements as more of the workflow gets automated. Custom benchmarking and monitoring show exactly which parts perform better or worse than expected. New models can be plugged in where they add value and skipped where they don’t.
The Bottom Line
Automating quotes and proposals isn’t just about saving time – though you’ll definitely get hours back each week. It’s about freeing your team to focus on strategy, relationship building, and the complex problem-solving that actually wins deals.
The technology is finally ready to support automated proposal generation, capturing the nuanced, institutional knowledge that makes your proposals effective. But success depends on building systems that work in tandem with your specific processes. Generic solutions miss the mark because they can’t capture the unspoken rules and expertise that separate good proposals from great ones.
Our three-step approach – from quick demo to foundational release to full implementation – means you can validate the concept before making major commitments. You’ll see results quickly and scale at your own pace. Most importantly, you stay in control throughout the process.
As AI models continue improving in capability and dropping in cost, having a flexible, model-agnostic system means you can take advantage of new developments without starting over. Your investment compounds over time.
Ready to see what automated proposal generation could look like for your business? Let’s start with an Effective Demo and find out.


